

Documentation Archaeology: How to Extract Knowledge from Abandoned Codebases with AI
Developers are no strangers to being thrown in a wild project where their ability to understand technical debt will be key to their survival and mental health. LLMs are amazing tools for this use-case

You need to work on a legacy project. The engineer who knew all about it left the company a year ago. Because the deadline was too tight, they didn’t take time to write a documentation. They also didn’t take a step back on the architecture and simply piled up technical debt. Welcome to what is essentially the digital version of Man versus Wild!
The good news is: this is a strong use-case for generative AI. Many of you will have strong reservations against clankers, but the general rule of thumb with LLMs is that they are good to make something long shorter.
More specifically, if you feed them some code they will perfectly understand what it does and most likely even why it does it. It also has strong knowledge of all business areas, so anything that isn’t pure company jargon should be picked up as well.
In this article, we will explore the less obvious techniques that will give you superhuman abilities to jump into any project that you have never seen before.
tldr/spoilers:
pfff src/**/*.py | llm -m 'gemini-2.5-pro' -s 'Please write a complete documentation of this project. I want a high-level overview of the main user flows. For each flow, generate proper Mermaid diagrams explaining the communication between all the different parties. Then go into the detail of each flow and explain the specific business decisions taken, edge cases, special rules, etc. For each step of the flow, tell me roughly where to look in the code in case I want to change something.'Workflow setup
We’ll use two main tools for this:
llm from Simon Willison1 gives a great CLI interface to various LLMs of the market
pfff from this author, which is simply a way to generate a context with source code in and pipe it into
llm
Given that they are both Python tool, I can only recommend to use uvx alongside with your shell’s aliasing system.
For fish users, that would be:
alias -s llm='uvx --with llm-gemini --with llm-claude-3 llm'
alias -s pfff='uvx pfff'For bash, add to your ~/.profile (or the relevant file to your configuration):
alias llm='uvx --with llm-gemini --with llm-claude-3 llm'
alias pfff='uvx pfff'Note how we add llm-gemini and llm-claude-3 as dependencies to llm. This is because there are many plugins for many providers.
If you are going to get only one plugin, you should get llm-gemini. This is by far the most useful LLM for the task at hand for a very simple reason. While most top-of-line LLMs have the same exact capabilities, Gemini shines with a 1 million token context window. This is big enough to fit a lot of entire codebases, and this will come in handy.
Once the plugin is installed, reach to Google’s AI Studio to grab an API key then run:
llm keys set geminiOnce this is done, you should be able to run something through Gemini, for example:
❯ echo "What is the answer to Life, the Universe and Everything? Give me the answer in JSON and only JSON." | llm -m gemini-2.5-pro
```json
{
"question": "What is the answer to the ultimate question of Life, the Universe and Everything?",
"answer": 42
}
```From this point on, you’re ready to go!
As a bonus however, you can have a look at the following tools:
Mermaid, a lib/tool for diagrams embeddable in Markdown (and supported by GitHub).
Typora, a nice desktop Markdown editor, which also happens to support Mermaid. Use any editor you want of course, but make sure to have one at hand for the rest of the article.
Project documentation
The LLM being a translation system, we often use it to translate a specification into code, with more or less effect. But on the other hand the code is the ultimate specification, which is fairly easy to translate back into English.
Good documentation
In order to get something useful, you first need to understand what it is that you seek.
A good documentation takes you through a story. Not of a princess sleeping in the highest room of the highest tower, but of the various user and data flows that compose the application. A transverse view if you prefer.
Apart from obscure Doxygen-generated documentations, all popular open source code essentially gives you a set of things:
A “Getting Started” guide, whose job is to get you doing something useful within 3 minutes, beyond which point you would lose patience and try another tool
A set of “Tutorials” or “Guides”, which will cover specific use-cases
And the “Reference” that goes into the nitty gritty details of how individual functions or pieces of function work
The “Getting Started” does not usually make sense in a corporate project, given that it has one instance and that’s it. It’s already running, you can observe it, not a problem.
The “Reference” well, you will see later but essentially that is not the biggest help at the moment.
Which leaves you with the topic-centric “Guides”. This is what you’re going to look at generating. What you want to know is, for each “story”:
Who speaks to whom in which order. This is what sequence diagrams are for, and they are entirely supported by Mermaid
Why this exists in a first place
Where to find it in the code
What are important implementation details that you should be aware of
All you need to do to get this, is to ask :)
From scratch
Let’s imagine that at this point, you have no useful documentation. Provided that your project is reasonably small (less than about 100k lines of code) and managed in Git, the first thing you need is to figure a way to list all useful code files.
A very obvious approach might be something like:
ls src/**/*.pyYou might otherwise want to look at all the non-binary files in Git:
git ls-tree -r --name-only HEAD | xargs -I{} sh -c 'git show HEAD:"{}" | grep -Iq . && echo "{}"'You are doing an important job of curating the context for the LLM: picking the right files, as exhaustive as possible, without also throwing huge useless content, confusing or contradictory information, etc.
In the next part we’ll be piping this into the LLM and you’ll start seeing results. If you are happy with the results it’s great, otherwise you might want to come back and revise the list of files to make it more relevant and/or try to make it fit into the context window if you exceeded it.
But don’t overthink it. Do something quick and dirty first. If you like it, go to the next step. And come back only if it fails.
That’s where pfff comes into action. It’s a very small tool whose sole purpose is to print the content of all the files you provided, alongside with their name so that the LLM can get a sense of the project’s structure.
Try it out:
pfff src/**/*.pyYou should end up with your terminal full of your source code. That’s what you will be sending to the LLM.
Now let’s send it with the question:
pfff src/**/*.py | llm -m 'gemini-2.5-pro' -s 'Please write a complete documentation of this project. I want a high-level overview of the main user flows. For each flow, generate proper Mermaid diagrams explaining the communication between all the different parties. Then go into the detail of each flow and explain the specific business decisions taken, edge cases, special rules, etc. For each step of the flow, tell me roughly where to look in the code in case I want to change something.'Adjust the prompt if needed, this one should give you a good first draft. You will receive in the output a long Markdown file containing the long-lost documentation of your project!
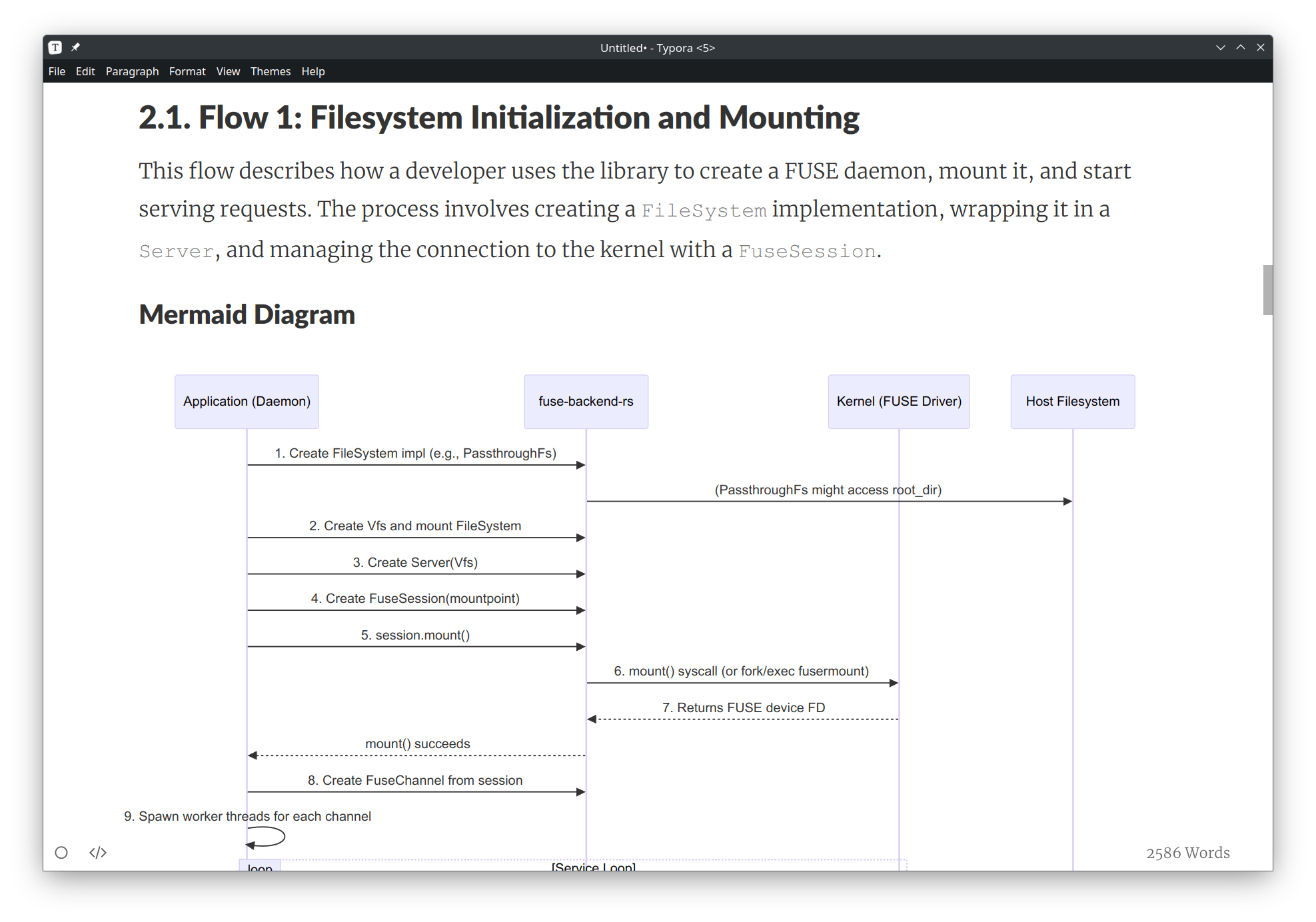
Copy/paste it into your favorite Markdown editor, you should be able to see all the lovely Mermaid flows and explanation of what is happening under the hood.
Keeping the documentation up-to-date
What is fantastic with this process is that you can also use it to keep the documentation up-to-date. Nothing easier:
pfff src/**/*.rs README.md Cargo.toml | llm -m gemini-2.5-pro -s 'Give me an updated version of the README which reflects the state of the code'You can integrate other ideas into your prompts, depending on the expected results:
“Fix all the docstrings that no longer match what the code actually does, or those who are incomplete. Do not rewrite text uselessly, only change things that need changing. Only give me the changed bits.”
“Compare the documentation with the current state of the code. Add sections that do not exist yet and adjust existing sentences that are inconsistent with the reality of the code. Avoid minor adjustments. Only give me the changed bits.”
Figuring the why
More often than not you will encounter functions who remain mysterious to you. The previous concepts can be laser-focused onto a specific part of the code. For example, you’re trying to understand how something specific works in the Linux kernel, which is millions of code thick. From the kernel’s root folder:
pfff fs/{ext4,fuse}/**/*.c | llm -m gemini-2.5-pro -s "The FUSE system has a lookup count system. From the implementer's point of view, what should I know? And which opcodes affect it?"And there you go. A straight answer from one of the most massive pieces of code that you will ever see.
Debugging
Another way LLMs are surprisingly efficient is in the unfolding of bugs. That one is not fool-proof, but you can still get very interesting results that will certainly help you to get going.
Let’s say that you have a weird bug. You open up your network inspector and grab the query that seems to be the issue:
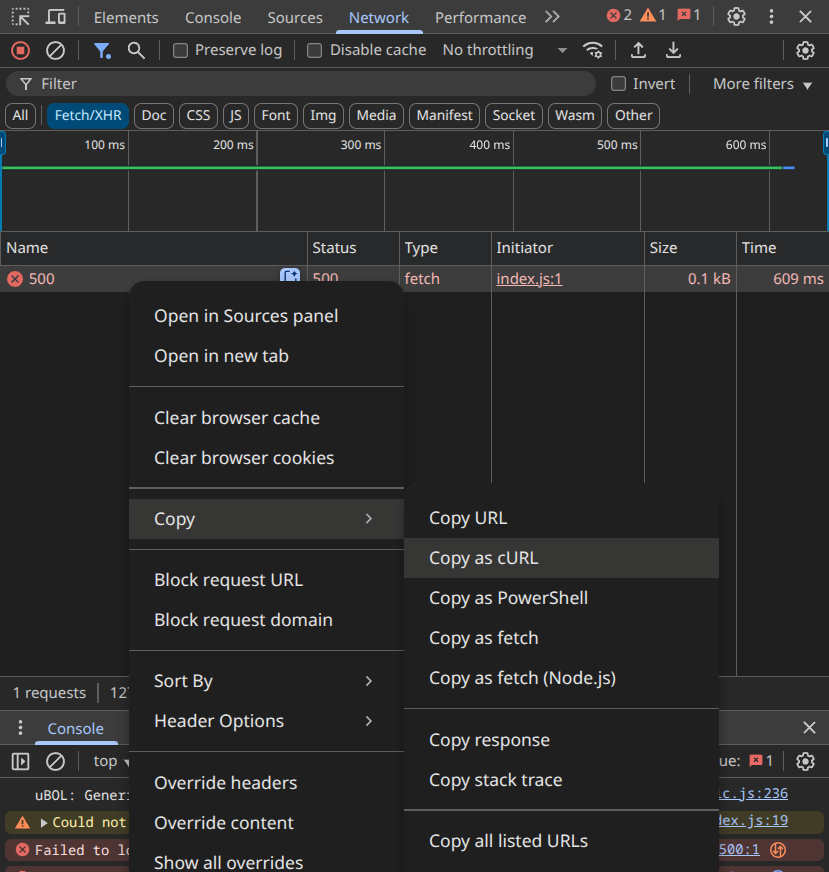
Then run it in your terminal, copy/paste the command + the output at the same time, and feed that again into the llm (I’ll use pbpaste here to paste the text easily, yes you can get it on Linux as well):
begin pbpaste; pfff **/*/*.py; end | llm -m gemini-2.5-pro -s "I'm getting an error in this query, how come?"You can usually ask more information than this, for example:
“Give me the steps to reproduce the bug”
“What would be a successful outcome?”
The actual diagnostic of the bug is often wrong or at least misleading. However the explanation of what happens and/or how to reproduce the bug is very helpful.
Here the example is using cURL, but you can of course get your information from somewhere else. For example a suspicious stack trace from Sentry, a more or less accurate description from the customer support, etc.
Conclusion
LLMs are very useful tools when used in the right way. Here you are shown how to leverage Gemini’s 1 million token context window in order to be able to dive quickly and efficiently into legacy projects. You were even shown how to curate your context to get interesting output out of behemoths such as the Linux kernel.
This comes a bit against current practices such as coding agents (see Cursor, Windsurf, Junie, etc). What makes them useful is their ability to interact with the real world without a human in the loop. But when it comes to efficiency, if a LLM can one-shot a given task—such as the kind of tasks showcased here—then you’re much better off piping everything at once rather than waiting 10 minutes for the agent to do its job.